


























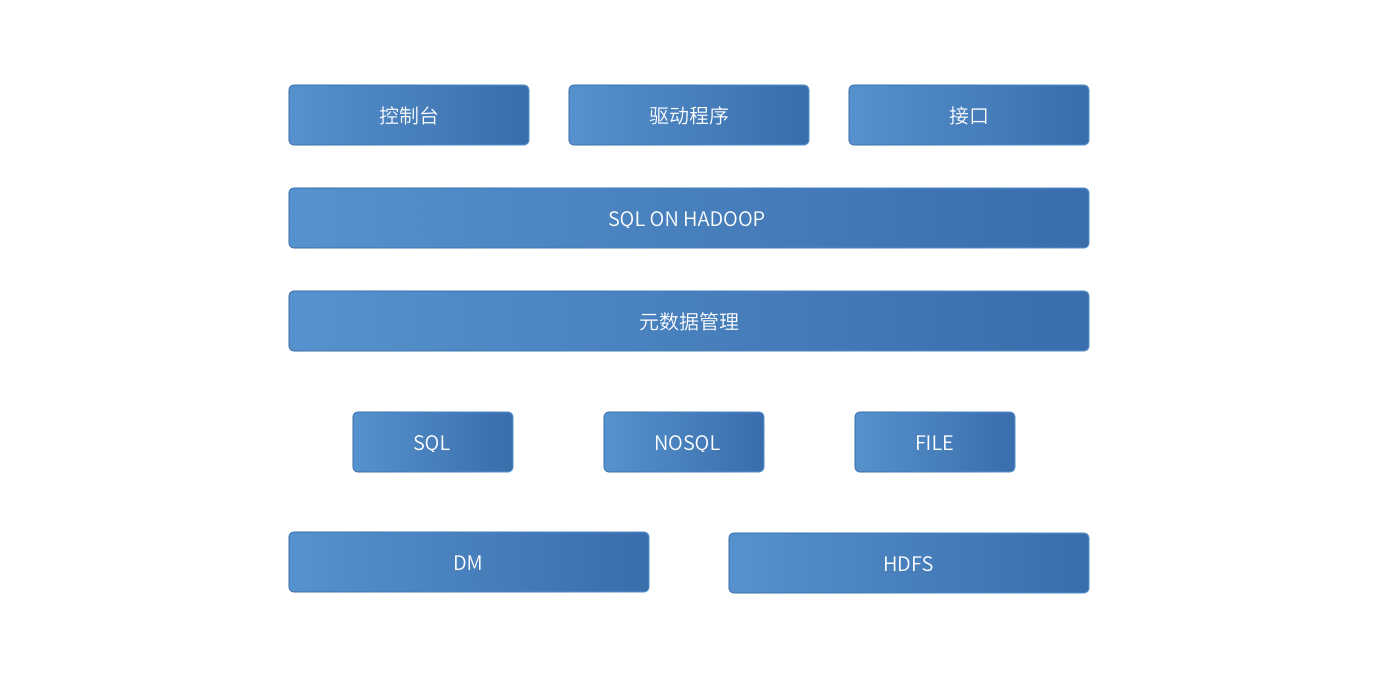
达梦启智大数据处理平台
达梦启智大数据处理平台(DMUDB)基于HADOOP,结合达梦自有的各类核心技术,能够承载海量的结构化数据、半结构化、非结构化数据,完成多种类型数据的统一承载、统一访问,支持海量数据的高可用、高可靠性、高安全,可结合HADOOP生态圈的其他产品,可以打造各种大数据应用解决方案。
简介
达梦启智大数据处理平台(DMUDB)通过HDFS结合达梦数据库打造海量数据的存储解决方案,提供统一的元数据解决方案,提供“SQL ON HADOOP”,提供WEB控制台、数据库驱动程序、应用查询接口等多种形式的服务方式。
核心特性
兼容HADOOP
达梦启智大数据处理平台完全兼容HADOOP生态圈的各类组件和接口,可以基于HADOOP提供各类大数据解决方案。


多种服务访问接口
达梦启智大数据处理平台提供标准的JDBC3.0驱动接口,提供DFS数据访问接口,提供WebService及HTTP REST数据访问接口。
高性能SQL引擎
达梦启智大数据处理平台“SQL ON HADOOP”查询引擎构建于分布式平台,支持将大型的SQL查询自动分解到多个查询节点上,查询性能随集群规模线性增长。


海量数据处理
达梦启智大数据处理平台支持PB级数据分析处理,具有强大的水平扩展能力,支持上千台的集群规模。





